|
Music Studio |
 The most important task of the audio interface is to convert an analog voltage signal to a digital stream of binary digits (bits) that represents the signal. This is the analog-to-digital conversion process in the block diagram of the audio interface. Its complementary process is the digital-to-analog conversion. This “digitization” process occurs at the interface between the analog world of the sound gear and the digital world of the computer. All of the “heavy lifting” of recording, editing, mixing, processing, and mastering the musical sound is done by software running on the computer – making this a computer-based recording system, or what is called an “inside-the-box” recording system. The digital signal processing that takes place in the computer’s CPU is quite sophisticated and very interesting. It’s a subject that occupies university courses and curricula, and relies on some advanced discrete mathematics. Here, I will only touch on the subjects of sampling and quantization. More information, on an introductory level, can be found at the excellent learning resource Digital Sound & Music: Concepts, Applications, and Science. “Digitization” of our analog signal consists of first sampling the voltage at a point in time, and then quantizing (assigning) that sample to the nearest regularly-spaced discrete voltage value. Each of these allowed discrete voltage values corresponds with a unique binary number This process repeats at regularly-spaced intervals in time. It’s instructive to look at this process using the figure below. 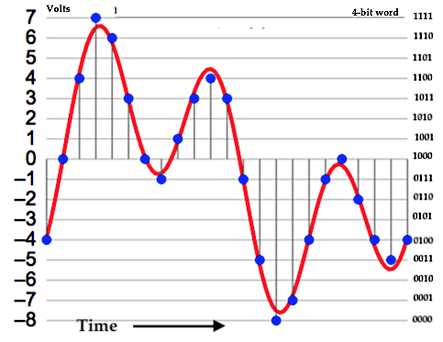 Analog Signal Sampling and Quantization (modified from Aquegg - Own work, CC BY-SA 3.0) The continuous red-colored curve is the analog voltage signal V(t). At regularly-spaced points in time, represented by the vertical grey lines, the signal is sampled, i.e., the voltage is measured. The quantization process then “rounds” this value either up or down to the nearest allowed discrete voltage value, represented by the horizontal grey lines. In this example, there are 16 allowed voltage levels, separated by 1-volt increments. A binary number of 4 bits is used to label each of these voltage levels, as shown on the right side of the figure. Clearly, sampling the analog waveform at a high rate and quantizing the voltage to many closely-spaced levels will yield a digitized waveform that is a “high fidelity” representation of the analog waveform . Let’s take a closer look at the sampling and quantization processes. Sampling How fast do we have to sample the analog waveform to get a digitized waveform that is capable of re-constructing the original sound with high fidelity ? Fortunately, there exists the Nyquist Theorem of mathematics that gives us guidance in this regard. If we look at the frequency spectrum of a complex sound signal waveform (Fourier Transform of V(t) ), we find that signal energy exists across a broad and nearly continuous range of frequencies that extends well beyond the human-audible range. The Nyquist Theorem states:
So, what happens if there exist frequency components in our signal that are higher than the Nyquist frequency f/2 ? Unfortunately, the spectral energies of these higher frequency components are ‘translated’ down into the frequency spectrum below f/2 in a process called “aliasing” . Not good -- this will lead to considerable distortion in our re-constructed analog waveform. To mitigate the effect of aliasing, we use an “anti-aliasing” low-pass filter on the signal (prior to the analog-to-digital converter) to remove the spectral energy at frequencies above f/2 . Unfortunately, practical low-pass filters cannot have an infinitely sharp cut-off characteristic at the frequency f/2 . To get around this fact, we actually sample at a slightly higher rate f ' > f . Now, as the low-pass filter response rolls off above f/2, it can provide adequate attenuation of signal energy at frequencies at and above f '/2 . If 20 kHz is taken as the highest frequency that humans can hear (just an average value, depending very much on age !), then the Nyquist frequency f/2 = 20 kHz, and the minimum sampling rate should be f = 40 kHz (40,000 samples per second !). For CD-quality sound, the industry standard sampling rate is 44.1 kHz. Another industry standard rate is 48 kHz, which is commonly used for the audio part of video and DVD production. Higher sampling rates are also readily available in most audio interface units. These sampling rates are multiples of two of the two base standard rates: 44.1 kHz, 88.2 kHz, 176.4 kHz and 48 kHz, 96 kHz, 192 kHz The 96 kHz sampling rate has been adopted as the de facto sampling rate for high-resolution recordings. Why do we need to use these higher sampling rates ? They produce large-sized data files and require substantial storage and media resources. But in their defense, it should be noted that the very color and timbre of the sounds of musical instruments come from the frequency spectral content that extends well above 20 kHz. While our ability to hear a pure sinewave tone may be dropping off gradually at higher frequencies, we may still retain a perception of a fuller color of a note sounded on a musical instrument if that high frequency content can be retained in the recorded audio waveform. There are varying opinions about this in the music recording and sound engineering community. Quantization When a sample is taken, the voltage amplitude of the signal at that moment in time is rounded to the nearest allowed voltage level which is represented by a unique binary number. The number of bits in this binary number is called the bit depth n , and determines the precision with which you can represent the sample amplitudes. The number of allowed voltage levels is given by: 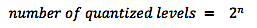 The resolution of the quantization process is dictated by the number of levels, and clearly this resolution increases rapidly with bit depth n. In the example figure above, the bit depth n = 4, so there are 2^4 = 16 levels. The resolution is the voltage increment between the discrete levels, which is 15 V / (16-1) = 1 volt in the example figure. Now, look what happens when the bit depth n = 16. There are 65,536 levels, and the resolution would be 15 V/(65,536-1) = 229 uV (229 x 10^-6 V) ! The difference between the original sample voltage and the quantized sample voltage that occurs from rounding is called quantization error. Quantization error is a form of correlated noise, since this error is an unwanted voltage added to the true amplitude voltage. Clearly, this error voltage is not a random process – it is strongly correlated with the signal. In this regard, the quantization error is better considered as distortion, as was done with correlated noise back in the posting on Noise. Because of this strong correlation with the true signal, the error voltage forms regular patterns in time that change in tandem with the original “correct” sound waveform. The error voltage itself constitutes an audio waveform, and this disagreeable sound could be very noticeable to a listener ! Another ‘source’ of distortion comes from clipping. Clipping occurs when the signal amplitude rises above the highest positive discrete level (the largest binary number, 1111 in the example figure) and falls below the lowest negative discrete level (the smallest binary number, 0000 in the example figure). In essence, the peaks of the sound waveform have been ‘clipped’ off. It’s possible that the error voltages during clipping are large enough to cause the total ruin of a sound recording. So recording at the proper audio levels is absolutely critical. Keeping distortion to a minimum is made possible by using a sufficiently high bit depth n . The industry standard for CD-quality audio is n = 16. It is generally considered to be the minimum depth for professional audio production. A bit depth n = 24 is the current standard for high-definition audio applications, and is often used in conjunction with the 96 kHz sampling rate. In my recording sessions, I use the 96k/24 combination exclusively. If higher bit depths are used, we run into a similar situation that was encountered with higher sampling rates – namely, does the resulting higher resolution go beyond the listener’s ability to discriminate it, and does it warrant the huge storage and media resources required. A final word here on audio dithering – it’s a technique used to reduce quantization error introduced in the analog-to-digital conversion process or in the conversion of an existing data stream to a lower bit depth. This latter process occurs in practice when data processing at the 32-bit or 64-bit level in your computer’s digital audio workstation is interpolated back to the target bit depth at 16 bit or 24 bit. Interestingly, dithering works by adding a very small amount of random noise into the quantization process, which breaks up the rounding error patterns that are correlated to the signal. In essence, a very small amount of random noise can reduce distortion caused by quantization error ! Next time, we’ll take a look at the topic of digital audio levels and dynamic range, which are intimately connected to bit depth.
|
Categories
All
Archives
May 2023
|
 RSS Feed
RSS Feed
